A Case for Redundant Array of Inexpensive Disks (RAID)
‘A Case for Redundant Array of Inexpensive Disks (RAID)’ by Patterson, Gibson, and Katz was published in SIGMOD 1988. The paper was the result of David Patterson asking Garth Gibson to learn about high performance storage systems and teach the UC Berkeley architects. The paper coined the term RAID and introduced a taxonomy for storage arrays. In doing so, it standardized the terminology and provided a toolkit to reason about performance and reliability in storage systems. Interestingly, the ‘I’ in RAID changed from ‘inexpensive’ to ‘independent’ at some point in the history of RAID because of the non-ideal connotation of inexpensive. In this post, we will discuss the motivation behind RAID, the different RAID levels and their tradeoffs, and end with a discussion on redundancy in modern distributed storage systems.
The motivation behind RAID was the slow improvement in disk performance in comparison to the performance improvements of CPU and main memory. CPU performance was nearly doubling every two years, and the memory subsystem performance kept up with the help of CPU caches. In contrast, the performance of hard disk drives improved slowly because disks are composed of mechanical components. The authors noted that the seeking latency reduced to half over 10 years (1971 to 1981) with no change in the rotational speed. Although the increasing data density in hard disks improved throughput, it was hard for disks to keep up with CPU, specially for random accesses whose performance is dominated by the seek latency.

The mismatch between performance of CPU and disks was troubling because a system is only as fast as its slowest component. For disk-bound applications, improvements in the CPU or memory performance do not translate to proportional improvements in application performance. For example, consider a disk-bound application that runs for 10 seconds but waits on disk for 9 out of the 10 seconds and performs computation only for 1 second. A 2x (i.e., 100%) faster CPU without any improvement in disk performance would reduce the application run time by just 5% — the application would still wait for disk 9 out of 10 seconds waiting on disk, and complete the computation in 0.5 second for a total run time of 9.5 second. This effect is mathematically described by Amdahl’s law. Amdahl’s law plays an important role in system design and performance debugging for systems in general. When designing systems, it is useful to have a balance across the performance of its components; when debugging performance issues, it is useful to identify and target the components that take up most of the execution time.
RAID’s fundamental idea is to replace a high-end costly disk with an array of low-end inexpensive disks to improve performance. The authors of RAID compared the performance, cost, and geometric characteristics of two classes of disks, namely, high-capacity enterprise-grade disks and low-capacity consumer disks. They observed that the per-seek-head performance of consumer disks was not too far behind that of enterprise disks and that consumer disks were in fact superior in other aspects like their power consumption and cost per bytes. They advocated eschewing a single large disk in favor of an array of low-end disks with the same total capacity. Such a system organization would have lower storage cost and power consumption with improved performance.
The performance improvement from using an array of disks comes from splitting the data across the disks and accessing them in parallel. For large data transfers, this would lead to increased bandwidth (bytes per second) as the disks operate in parallel to simultaneously access their corresponding portion of the overall data. For small data transfers, such an organization would lead to higher IOPS (IO operations per second) as the disks can individually access the small data chunks in parallel without getting bottlenecked on a single seek head. So an array of disks improves performance, and reduces cost and power consumption. This sounds like a free lunch, but there is never a free lunch, so what is the catch?

The challenge in using an array of disks is that it increases the chance of losing the data. Notwithstanding the lower reliability of low-end disks to begin with, spreading data across multiple disks as opposed to keeping it in a single disk increases the probability of data loss. Intuitively, if the probability of data loss on a single disk is p, the probability of data loss for data spread across n disks is 1 — (1 — p)^n (i.e., 1 — probability that none of the n disks lose data). As n increases, the probability of data loss increases.
The more rigorous and mathematical way of thinking about data loss for disks (or an array of disks) is in terms of a statistical estimate called Mean Time To Failure (MTTF). Despite what the name implies, MTTF of a disk should not be interpreted as the average time before a disk loses data. As such, being a statistical estimate, MTTF is practically meaningless for a single disk. The way to interpret MTTF is by considering a large collection of disks. For a large collection of disks, the average time before any data loss across any of the disks, i.e., the MTTF of the collection, is the MTTF of an individual disk divided by the number of disks in the collection. MTTF of a collection of disks = MTTF of disk / number of disks in collection. MTTF is the standard way of reasoning about storage systems, and higher MTTF implies more reliable storage.
The problem with using an array of disks instead of a single disk is that it leads to a lower MTTF (MTTF of array = MTTF of disk / number of disks in array).
RAID’s solution to the problem of reduced reliability is to store data with some redundancy in the array of disks (i.e., the R in RAID). By adding redundancy, a RAID system can tolerate data loss (because of a disk failure) by reconstructing the lost data onto a new disk using the redundant data. The RAID paper introduced a taxonomy of RAID organizations with different ways of storing redundancy which affects the performance of the RAID system. Each of these RAID organizations consists of a RAID controller that mediates data accesses across the disk array. We will now discuss the various RAID levels:
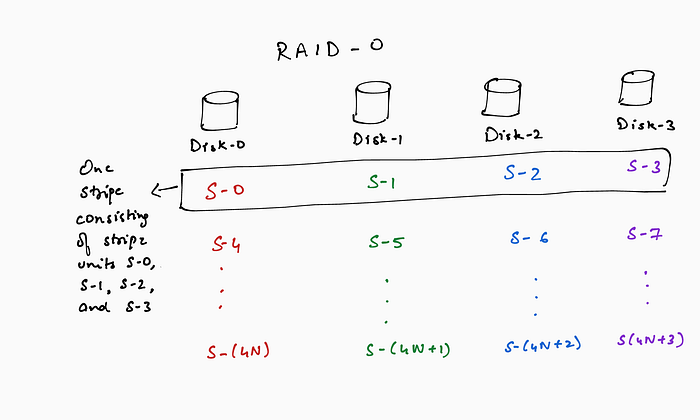
RAID-0: Although not present in the original paper, RAID 0 is commonly used to refer to an array of disks with data striped across the disks but without any redundancy. As discussed earlier, RAID-0 provides improved performance because of data striping, but the lack of redundancy leads to reduced reliability of the storage system.
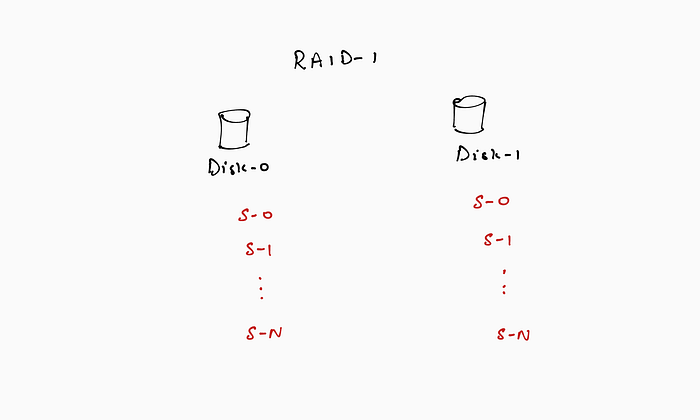
RAID-1: This refers to an organization wherein the same data is mirrored across two disks. RAID-1 does not offer any performance improvements (data is not spread across disks) and might even hurt write performance because data needs to be written to both disks. It does however, improve reliability because the system can tolerate the failure of one of the disks.
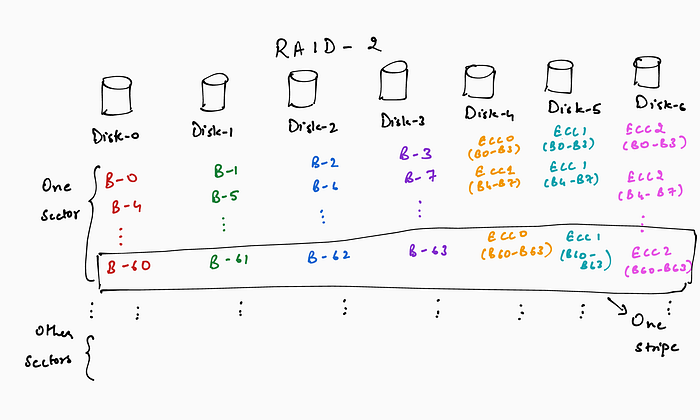
RAID-2: This organization uses error correcting codes (ECC) as redundant data. Data is striped across the disks at a byte granularity and ECC bytes are stored corresponding to the data bytes. For example, in an array of 7 disks, 4 disks store data bytes and the remaining 3 disks store ECC bytes.
Using ECC for redundancy in RAID-2 turned out to be an overkill. ECCs are used to detect as well as correct errors. For example if one of the disks returned a corrupted byte, the ECC would be able to catch the corruption and correct it. However, a common failure mode for disks is actually fail-stop mode, wherein the disk either provides the right data or does not provide data at all. In other words, the disk can self-detect a failure and the RAID system only needs enough redundancy to be able to correct it. It is interesting to note that to identify the disk failure and not return data (i.e., the fail-stop mode of disks), the disk controllers internally use ECC for each of the disk sectors. Given the fail-stop mode of disks, having ECC in RAID was wasteful of disk capacity.
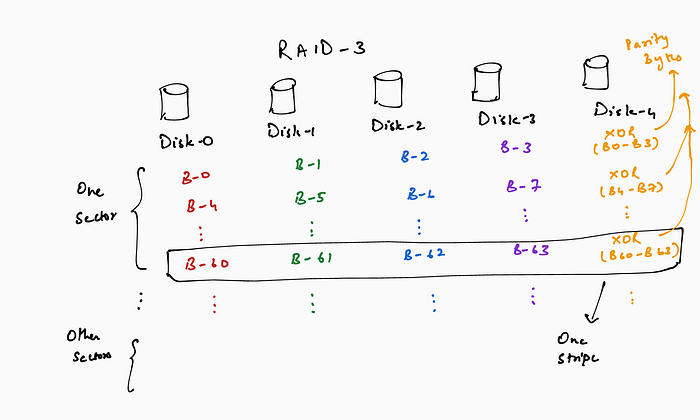
RAID-3: RAID-3 replaces the ECC with a single parity (XOR) byte corresponding to data bytes. For example, in an array of 5 disks, 4 disks store data bytes and the 5th disk stores the corresponding parity bytes. In case of a disk-failure, the controller can reconstruct lost data (from a failed disk) using the parity data.
RAID-3 (and RAID-2) use byte-level striping of data across the disks and are ill-suited for small (say 1 sector) accesses. This is because the sector’s amount of data is spread across the disks, but each disk has to access an entire sector (minimum addressable unit) only to waste a lot of the data. Small writes are particularly penalized because a write to only a portion of the sector requires the controller to read the entire old sector from the disk, modify it using the portion of the new data, and write back the entire sector. This cycle is called a read-modify-write. Large data accesses that exceed the sum of the sector size across all data disks benefit from the parallel accesses.
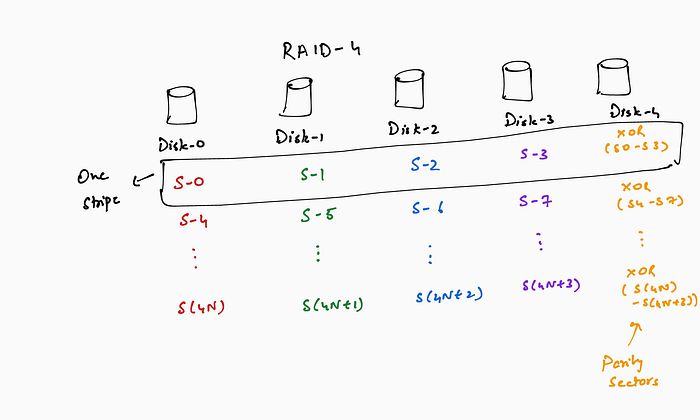
RAID-4: RAID-4 uses a sector-granular striping and uses a parity sector for each set of data sectors. Similar to RAID-3, with an array of 5 disks, 4 disks store data and 1 disk stores parity. The difference is that each of the data disks store an entire sector’s worth of contiguous data (i.e., data is striped at the granularity of a sector).
RAID-4 addresses the small (less than sector size times the number of data disks) access problem of RAID-3. However, RAID-4 still requires a read-modify-write for the parity sector for a small write. For a small write (say 1 sector) the controller cannot compute the new parity sector using just the new data. This is in contrast to a large write (spanning sectors across all the data disks) wherein the controller can compute the new parity sector using the new data. Instead, for the small write, the controller needs to read the corresponding unmodified data sectors from all the data disks, compute the new parity sector and write back the new data and parity sectors.
This problem of updating redundancy for small writes (i.e., a write that does not span the corresponding data in all data disks) affects RAID-3 and RAID-2 as well. One of the advantages of using parity (RAID-3 and RAID-4) instead of ECC (RAID-2) is that the new parity can be computed using just the old parity, soon-to-be-old data and the new data. This is because parity is just addition in binary — hence the new parity can be computed by subtracting the soon-to-be-old data and adding the new data. For RAID-4 this means that in case of a small write, the controller only needs to read the soon-to-be-old data and the old parity sectors instead of all the unmodified data sectors to compute the new parity.
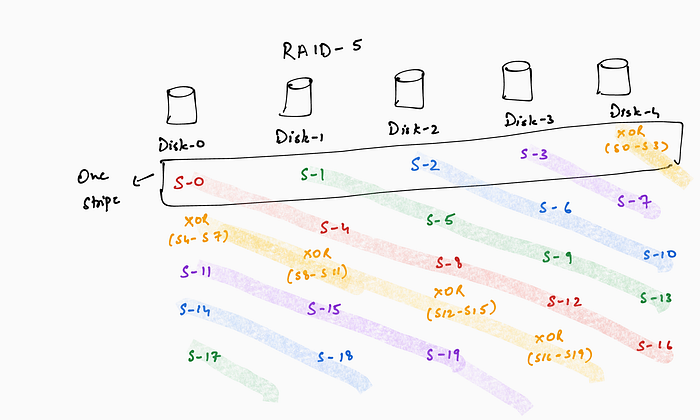
RAID-5: RAID-5 spreads the parity sector across the disks in a round-robin manner such that each disk acts as a data disk for some sectors and as a parity disk for other sectors.
The motivation behind spreading the parity sector is to avoid the scenario wherein the parity disk (i.e., the disk containing the parity sectors) in RAID-4 becomes a bottleneck for small writes (which require a read-modify-write on the parity disk). With the parity sectors spread out, two small writes in RAID-5 can potentially proceed in parallel.
RAID systems have multiple interesting aspects, some of which we briefly discuss below:
- A key design choice for RAID systems is that of the stripe unit size, i.e., the granularity at which data is striped across the disks. For example, RAID-2 and RAID-3 stripe data at a byte granularity, which is a sub-optimal choice in hindsight, and are rarely, if ever, used in practice today. Most systems use a stripe unit size of a sector (like RAID-4 and RAID-5) or larger, but the optimal stripe unit size is hard to determine as it is workload dependent. Smaller stripe units leverage parallelism for large accesses leading to improved throughput. However it can also increase latency because the disk heads in all the disk must perform a seek and the largest seek time across all the disks determines the latency. In contrast, with large stripe units, some of the accesses require seeking on only a single disk, improving latency but at the cost of reduced parallelism.
- Another interesting performance metric for RAID systems is their degraded read performance. This is the read performance when one of the disk has failed. For example, for RAID-4 and RAID-5, the degraded read performance for large reads is comparable to that of large reads without any failure — the controller reads the same number of sectors, just that one of the sectors is a parity sector for a degraded read and the controller has to perform some computation to construct the failed sector using the parity and existing data sectors. The degraded read performance is particularly relevant for repairing a failed disk in a RAID system. Upon failure, data must be recovered and written on a new disk using degraded reads.
- The RAID levels discussed here can tolerate only a single disk failure. However, this became a problem with increasing disk capacities. As disk capacities increased, so did the time to recover data for a failed disk onto a new disk. Soon enough, this time for recovery was large enough that there was a real risk of another disk failure during the repair process, which would render the RAID system irrecoverable. Consequently, there were RAID systems developed to tolerate 2 (or even more) simultaneous disk failures.
- RAID systems also face the challenge of crash consistency (the data on disks in the array is inter-related and must be updated atomically) and solve it using one of the standard mechanisms (e.g., battery backed cache or journaling).
Redundancy in modern distributed storage systems looks different than the RAID systems, but is nevertheless rooted in the RAID concepts. The major driving difference is the scale — modern distributed storage systems operate at a much larger scale with 100s to 1000s of disks and machines. Instead of grouping disks into arrays, modern distributed storage systems think about redundancy at a stripe level. For example, one of the stripe units on disk 80 can have corresponding stripe units on disk 10 and 133, while another stripe unit on disk 80 can have corresponding stripe units on disk 47, 200, and 271 (yes the number of stripe units can also vary!). Spreading stripe units across disks improves load balancing and also helps with recovery. If a certain disk becomes a bottleneck for the system performance, some of the hot stripe units from the disk can be spread to other disks. The loose coupling of disks with stripe units enables such load balancing. For recovery of a failed disk, data can be read from and written to multiple disks in parallel. In the above example, if disk 80 fails, the first stripe unit may be recovered on disk 28 by reading data from disks 10 and 133, while the second stripe unit may be recovered on disk 76 by reading data from disks 47, 200, and 271. The downside of the increased scale (in number of disks) is the increased probability of disk failures and data loss. Modern distributed storage systems incorporate more redundancy per stripe to tolerate more disk failures. This redundancy is often (but not always) in the form of Reed-Solomon codes, which have complex tradeoffs of their own.
Despite the decades of advances in storage architectures and the increased scale, RAID concepts are still useful for reasoning about storage systems’ performance and reliability. Disk performance is still far behind CPU performance (even with SSDs), MTTF is still the standard metric for quantifying the reliability of a stored data, and the performance of small writes and degraded reads are still important design aspects.
